TDM: Trajectory Data Minning
دادهکاوی خط سیرTDM: Trajectory Data Minning
دادهکاوی خط سیر
یادگیری عمیق چیست؟
در سالهای گذشته شاهد افزایش فزایندهی تعداد کاربران اینترنت بودیم. شرکت Netcraft که خدمات سایبری و امنیت ارائه میدهد، در آماری که در وبسایت خود منتشر کرده تعداد وبسایتهای فعال سالهای گذشته را گزارش میدهد. این آمار در نمودار شکل ۱ نشان داده شده است. شرکت Netcraft در پایشی که در جولای ۲۰۲۱ انجام داده، تعداد وبسایتهای موجود را 1,216,435,462 اعلام کرده. در نمودار شکل ۱ مشخص است که تعداد وب سایتها در سالهای گذشته سیر صعودی داشتهاند. البته نزول نسبی نمودار در سالهای اخیر را میتوان به ظهور شبکههای اجتماعی و تمایل بیشتر کاربران اینترنت به استفاده از این شبکهها نسبت داد. این رشد فزاینده در تعداد وبسایتها، با افزایش محتوای موجود در اینترنت و تولید داده در سطح کلان همراه است. به همین دلیل است که عصر حاضر با نام عصر کلان داده نامگذاری شده است.
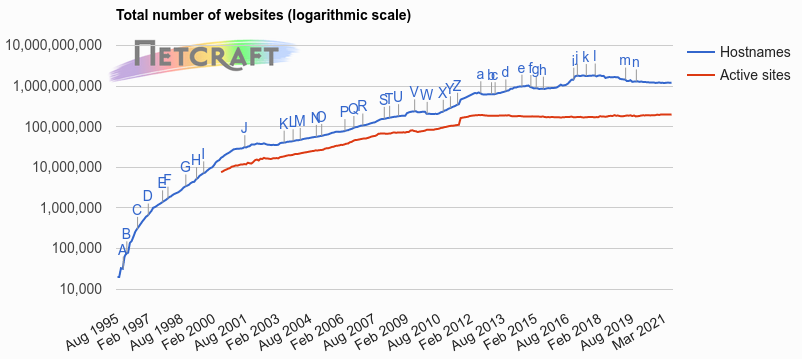
شکل
۱-
تعداد
وبسایتهای فعال در سالهای گذشته، به
گزارش شرکت
Netcraft.
علاوه بر وبسایتها شبکههای اجتماعی نیز به تولید محتوا میپردازند. تخمین زده میشود تعداد ویدیوهای یوتیوب ۱۰۰ میلیون عدد باشد و هر روز۶۵۰۰۰ ویدیو در یوتیوب بارگذاری شود. بنا بر آماری که تا ماه نوامبر ۲۰۱۰ منتشر شده، در هر ۶۰ ثانیه، ۱۳ ساعت فیلم در یوتیوب بارگذاری میشود. در سایر شبکههای اجتماعی نیز آمار مشابهی وجود دارد. هر روز ویدیوها و عکسها و متنهایی در حجم بسیار زیاد توسط کاربران شبکههای اجتماعی برای اشتراک با دیگران بارگذاری میشوند. در کنار همهی این کلان دادهها، سنسورهای مختلفی نیز وجود دارند که اطلاعات محیطی را جمعآوری میکنند. از جمله GPSها، دوربینهای نظارتی، سنسورهای سنجش لرزههای زمین، اطلاعات مربوط به آزمایشگاهها و بسیاری دیگر نیز دادههای حجیمی هستند که گرچه مانند شبکههای اجتماعی و وبسایتها عمومی نیستند اما به همان اندازه به پردازش و تحلیل نیاز دارند.
این سیل حجیم از دادهها که بیوقفه تولید شده و ذخیره میشوند شامل اطلاعات بسیار با اهمیت و مفیدی هستند. به عنوان مثال تمایلات سیاسی مردم در جریان تبلیغات قبل از انتخابات میتواند از تحلیل پیامهای رد و بدل شده در شبکههای اجتماعی بدست آمده و در تصمیمگیریهای احزاب سیاسی مورد استفاده قرار گیرد. و یا شرکتهای تولیدی یا خدماتی میتوانند میزان رضایت مشتریان خود را بر اساس تحلیلهای انجام شده در شبکههای اجتماعی بررسی کرده و نیازمندیهای آنها را برای تولید محصولات و یا ارائهی خدمات در آینده، رصد نمایند.
ابزارهای مختلفی برای پردازش و تحلیل دادهها در دسترس قرار دارد و تکنیکهای مختلف دادهکاوی و یادگیری ماشین مهمترین آنها هستند. در سالهای اخیر با ظهور یادگیری عمیق، پیشرفتهای خوبی در زمینهی تحلیل دادهها صورت گرفته است و حتی در مواردی گوی سبقت را از انسان و مغز بسیار پیچیده و پیشرفتهی او ربوده. برای اینکه به درک درستی از چیستی یادگیری عمیق برسیم لازم است که ابتدا تعریفی از یادگیری ماشین ارائه نماییم.
استخراج اطلاعات مفید از حجم بسیار زیاد دادههایی که هر روز و هر ساعت در اینترنت، وبسایتها، شبکههای اجتماعی، سنسورها و انواع منابع دیگر تولید میشود، مستلزم روشهای خودکار تجزیه و تحلیل دادهها است. این همان چیزی است که یادگیری ماشین ارائه میدهد.
یادگیری ماشین، به طور خاص، به مجموعهای از روشها اطلاق میشود که میتوانند الگوهای دادهها را بطور خودکار تشخیص دهند. نتایج بدست آمده از این تشخیصها، توسط سیستم برای پیشبینی دادههای آینده و یا انجام انواع دیگر تصمیمگیریها مورد استفاده قرار میگیرد (Goodfellow et al., 2016; Murphy, 2012; Pedrycz and Chen, 2020).
معرفی یادگیری ماشینی به رایانهها این امکان را داد تا با مسائل مربوط به دانش دنیای واقعی مواجه شده و تصمیماتی را که به نظر ذهنی میرسند، اتخاذ نمایند. یک الگوریتم سادهی یادگیری ماشین به نام رگرسیون لجستیک میتواند تعیین کند که آیا زایمان سزارین توصیه میشود یا نه (Mor-Yosef et al., 1990). یک الگوریتم سادهی یادگیری ماشین به نام بیس ساده میتواند ایمیلهای قانونی را از ایمیلهای اسپم جدا کند (Goodfellow et al., 2016). دامنهی کاربرد وسیعی برای یادگیری ماشین وجود دارد. از جمله میتوان به بیوانفورماتیک، تشخیص تقلب، تجزیه و تحلیل بازارهای مالی، تشخیص تصویر و پردازش زبان طبیعی (NLP) اشاره کرد (Pedrycz and Chen, 2020).
یکی از شاخههای یادگیری ماشین که در دههی گذشته به عنوان یک استاندارد طلایی در جامعهی یادگیری ماشین مطرح بوده یادگیری عمیق است (Alzubaidi et al., 2021). یادگیری عمیق در حال حاضر پرکاربردترین رویکرد محاسباتی در عرصهی یادگیری ماشین است که قادر به یادگیری حجم عظیمی از دادههاست (Alzubaidi et al., 2021). شبکههای عصبی در دههی ۱۹۹۰ با محدودیتها و معضلاتی مواجه بودند که کارایی آنها را به عنوان یک ابزار یادگیری ماشین کاهش میداد. Geoffery Hinton،ر Yann LeCun ور Yoshua Bengio با تلاشهای پیگیرانهی خود در دههی پایانی قرن بیستم و دههی ابتدای قرن بیست و یک، برای غلبه بر کاستیها و محدودیتهای شبکههای عصبی، روشها و معماریهایی را ابداع کردند که به یادگیری عمیق معروف شد. آنها تکنیکی را ارائه کردند که سیستمهای کامپیوتری را قادر میسازد با تجربه و یادگیری از دادههای ورودی بهبود یابد. یادگیری عمیق قدرت و انعطافپذیری در یادگیری را با بازنمایی دنیای دادهها به صورت سلسله مراتبی از مفاهیم تو در تو، افزایش میدهد (Goodfellow et al., 2016).
همانگونه که در شکل ۲ نشان داده شده یادگیری عمیق نوع خاصی از یادگیری ماشین است (Goodfellow et al., 2016) که درواقع به شبکههای عصبی عمیق اشاره دارد. نوعی از شبکه عصبی که به صورت پرسپترون چندلایه مدل شده و بدون هرگونه تنظیم دستی برای استخراج ویژگیها، با هدف بازنمایی مجموعه دادهها، آموزش میبیند. همانگونه که از نامش پیداست، شبکه عصبی عمیق شامل تعداد لایههای بیشتر است و در نقطهی مقابل یادگیری کم عمق ( Shallow Learning) قرار میگیرد (Shrestha and Mahmood, 2019).

شکل
۲–
نمودار
جایگاه یادگیری عمیق نسبت به یادگیری
ماشین (Goodfellow
et al., 2016)
حرکت از یادگیری کم عمق به یادگیری عمیق اجازهی نگاشت توابع پیچیده و غیر خطی را میدهد، که در معماریهای کم عمق امکانپذیر نبود. این بهبود با ازدیاد واحدهای پردازشی قویتر مثل GPU و مقدار زیادی از مجموعه دادهها (big data) برای آموزش، کامل شد. با وجود اینکه GPUها قدرت کمتری نسبت به CPUها دارند، تعداد هستههای پردازشی موازی در آنها از تعداد هستههای پردازندههای CPU بیشتر است. این امر باعث میشود که GPUها برای پیادهسازی شبکههای عصبی عمیق مناسبتر باشند (Shrestha and Mahmood, 2019).
زمینهی یادگیری عمیق در چند سال گذشته به سرعت رشد نموده و نتایج برجستهای کسب کرده که با عملکرد انسانی مطابقت دارد و حتی از آن نیز فراتر رفته. از یادگیری عمیق به طور گسترده در طیف وسیعی از کاربردهای سنتی استفاده شده است. در حوزههای امنیت سایبری، پردازش زبان طبیعی، بیوانفورماتیک، روباتیک و کنترل، پردازش اطلاعات پزشکی و بسیاری حوزههای دیگر، توانسته از تکنیکهای سنتی و شناخته شدهی یادگیری ماشین پیشی بگیرد. گرچه یادگیری عمیق از شبکه عصبی معمولی مشتق شده است، اما به طور قابل ملاحظهای از نسخههای قبلی خود بهتر عمل میکند (Alzubaidi et al., 2021).
منابع:
Alzubaidi, L., Zhang, J., Humaidi, A.J., Al-Dujaili, A., Duan, Y., Al-Shamma, O., Santamaría, J., Fadhel, M.A., Al-Amidie, M., Farhan, L., 2021. Review of deep learning: concepts, CNN architectures, challenges, applications, future directions. J. Big Data 8, 53. https://doi.org/10.1186/s40537-021-00444-8
Goodfellow, I., Bengio, Y., Courville, A., 2016. Deep learning, Adaptive computation and machine learning. The MIT Press, Cambridge, Massachusetts.
Mor-Yosef, S., Samueloff, A., Modan, B., Navot, D., Schenker, J.G., 1990. Ranking the risk factors for cesarean: logistic regression analysis of a nationwide study. Obstet. Gynecol. 75, 944–947.
Murphy, K.P., 2012. Machine learning: a probabilistic perspective, Adaptive computation and machine learning series. MIT Press, Cambridge, MA.
Pedrycz, W., Chen, S.-M. (Eds.), 2020. Deep Learning: Concepts and Architectures, Studies in Computational Intelligence. Springer International Publishing, Cham. https://doi.org/10.1007/978-3-030-31756-0
Shrestha, A., Mahmood, A., 2019. Review of Deep Learning Algorithms and Architectures. IEEE Access 7, 53040–53065. https://doi.org/10.1109/ACCESS.2019.2912200


























