TDM: Trajectory Data Minning
دادهکاوی خط سیرTDM: Trajectory Data Minning
دادهکاوی خط سیر
انواع معماری یادگیری عمیق
در یادداشت قبلی به چیستی یادگیری عمیق پرداختیم. یادگیری عمیق نوع خاصی از یادگیری ماشین است (Goodfellow et al., 2016) که درواقع به شبکههای عصبی عمیق اشاره دارد. انواع مخلفی از معماریهای شبکههای عصبی برای یادگیری عمیق ارائه شده. در نوشتار حاضر قصد داریم انواع معماریهای اصلی شبکههای عصبی عمیق را به صورت مختصر معرفی نماییم. در یادداشتهای بعدی همین وبلاگ جزئیات بیشتری از این معماریها ارائه خواهد شد.
شکل ۱ نگاهی کلی دارد به معماریهای اصلی شبکههای عصبی عمیق. در این شکل معماریهای خاص هر دسته نیز دیده میشوند. به طور کلی، روشهای مختلف یادگیری عمیق را میتوان در چند دسته طبقهبندی کرد. در کتاب (Pedrycz and Chen, 2020) این طبقهبندی در سه دسته انجام شده است که عبارتند از: شبکه های عصبی کانولوشن (Convolutional Neural Networks-CNNs) ، شبکه های بدون نظارت پیش آموزش دیده (Pretrained Unspervised Networks-PUNs) و شبکه های عصبی بازگشتی (Recurrent/Recursive Neural Networks-RNNs). شبکههای عصبی پرسپترون چند لایه (Multilayer Perceptrons-MLPs) با تعداد لایههای زیاد (بیشتر از ۳ لایه) جزو اولین شبکههای عصبی بودند که برای یادگیری عمیق مورد استفاده قرار گرفتند. به همین دلیل، همانگونه که در شکل ۱ دیده میشود، ما در اینجا MLP را نیز به طبقهبندی انواع معماری شبکههای عصبی عمیق اضافه کردهایم.
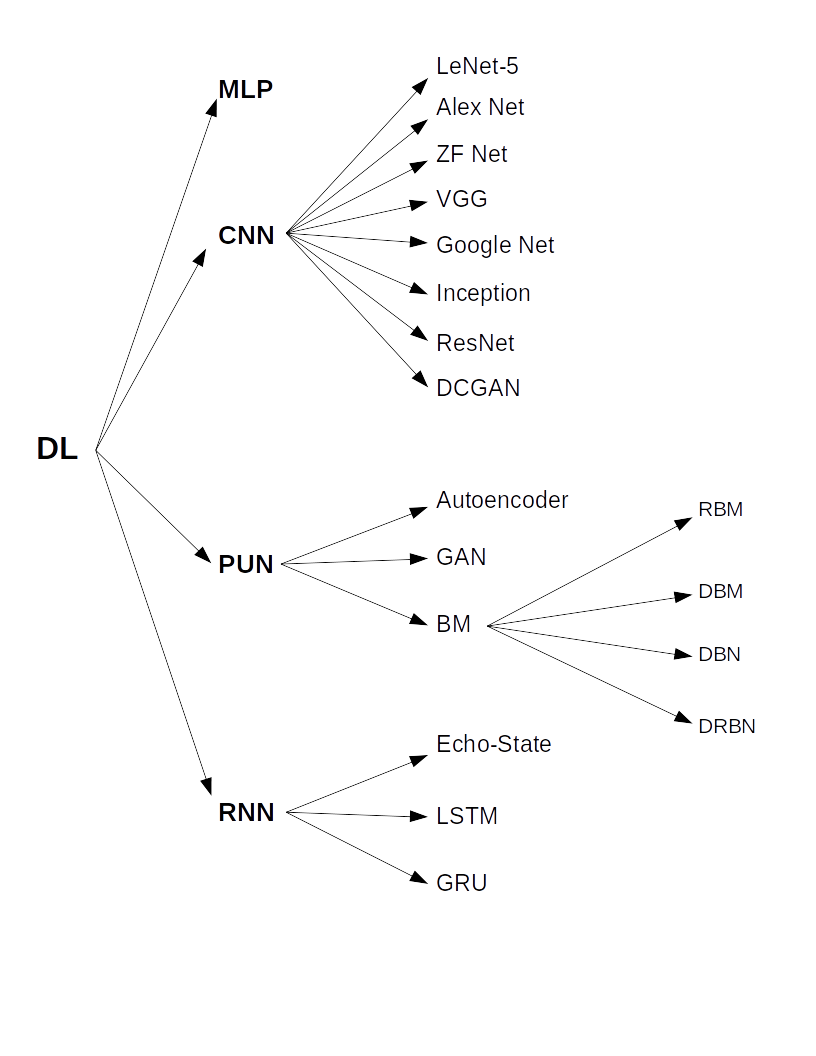
شکل ۱-طبقهبندی انواع معماریهای اصلی شبکههای عصبی عمیق
پرسپترون چند لایه (MLP) که در دستهی شبکههای عصبی پیشرو قرار میگیرد از اولین معماریهای شبکههای عصبی بود که برای یادگیری عمیق مورد استفاده قرار میگرفت. در شبکهی MLP نورونها در چندین لایه که پشت سر هم یکی پس از دیگری قرار دارند سازماندهی میشوند؛ به صورتی که خروجی هر لایه ورودی لایهی بعدی است. این شبکهها که با الگوریتم پسانتشار آموزش میبینند در صورتی که قدرت محاسباتی نامحدود در اختیار داشته باشند، قادر هستند هر مسئلهی خطی و غیر خطی را حل نمایند. البته در این راه با چالشها و مسائلی نیز روبرو هستند. از جمله محدودیتهای مربوط به قدرت محاسباتی سختافزارها، بیش برازش (overfitting)، محو شدگی گرادیان (vanishing gradient) و انفجار گرادیان (exploding gradient).
نوع دیگری از شبکههای عصبی پیشرو که در شکل ۱ نشان داده شده شبکههای عصبی کانولوشن (CNN) هستند. این شبکهها برای دادههای grid-structured طراحی شدهاند و برای مهندسی ویژگیهای سلسلهمراتبی با عمق زیاد مناسب هستند. اگر در مجموعه دادهها وابستگیهای فضایی وجود داشته باشد شبکههای عصبی کانولوشن به خوبی این دادهها را تحلیل کرده و این وابستگیها را شناسایی میکنند. عکسهای دو بعدی و دادههای دنبالهای (sequantial data) مثل متن و سری زمانی مثالهایی از اینگونه دادهها هستند.
الگوریتمها و روشهای یادگیری عمیق متکی به مجموعه دادههای آموزشی هستند و برای یادگیری به دادههای حجیم نیاز دارند. اما در بسیاری از کاربردها با محدودیت مجموعه دادههای استاندارد برای آموزش و آزمایش روشهای یادگیری ماشین مواجه هستیم. بر این اساس تولید داده (Data Generation) و استخراج ویژگیها (feature extraction) از کاربردهای بسیار مهم مبحث یادگیری عمیق به حساب میآیند.
برای اینکه مجموعه دادهی محدود و کوچک اولیه را تقویت کرده و مجموعه دادهی بزرگتری برای آموزش شبکه تولید نماییم، تکنیکهای گوناگونی وجود دارد. به عنوان نمونه میتوان از معماریهای Generative Adversarial Networks یا به اختصار GAN و Autoencoders نام برد. این شبکهها میتوانند برای بهبود یادگیری مدلها بر اساس مجموعه دادهی اصلی اولیه دادههای مصنوعی تولید کنند. هر دو این معماریها به خانوادهای از معماریهای شبکههای عصبی عمیق با نام شبکههای بدون نظارت پیش آموزش دیده (Pretrained Unsupervised Network - PUN) تعلق دارند. شبکهی بدون نظارت پیش آموزش دیده یک مدل یادگیری عمیق است که از یادگیری بدون ناظر استفاده میکند تا هر لایهی پنهان در یک شبکه عصبی را آموزش دهد تا مطابقت دقیقتری با مجموعهداده داشته باشد. انواع شبکههای بدون نظارت پیش آموزش دیده شامل Autoencoders, Deep Belief Networks (DBN), Deep Restricted Boltzman Machine و Generative Adversarial Networks (GAN) (Patterson and Gibson, 2017) هستند.
Autoencoder یک روش استخراج ویژگیها بدون ناظر است که با هدف کاهش ابعاد دادههای ورودی به کار یادگیری بازنمایی دادهها میپردازد. در واقع در کاربردهایی که در آنها ابعاد دادهها زیاد است و به سبب آن حجم محاسبات زیاد میشود، میتوان با این شبکه ابعاد ورودی را کاهش داد.
یکی از معماریهای جالب توجه در شبکههای عصبی عمیق که در سالهای اخیر بسیار از آن استفاده میشود، GAN است که میتواند هر توزیع دادهای را در هر زمینهای تقلید کند. این معماری نیز مانند Autoencoder جزو مدلهای یادگیری بدون نظارت است. این شبکه از یادگیری بدون ناظر برای آموزش دو مدل به صورت موازی استفاده میکند تا در تقابل با یکدیگر بتوانند دادههای جعلی بسازند که بسیار شبیه به دادههای واقعی باشد. در مواقعی که با حجم محدودی از دادهها مواجه هستیم و در حوزهها و کاربردهای پیچیده که نیازمند حجم زیادی از دادههای آموزشی هستند، برای افزایش کیفیت آموزش مدلهای یادگیری، میتوانیم از GAN برای مدلسازی مولد جهت تولید دادههای بیشتر استفاده کنیم. این شبکه بهخصوص در حوزههای یادگیری تقویتی موفقیتهای خوبی بدست آورده است.
دستهی دیگری از معماریها که در زیر مجموعهی معماریهای از نوع PUN قرار میگیرند، ماشینهای بولتزمن و انواع مختلف آنها هستند. ماشینهای بولتزمن با این هدف طراحی و ساخته شدند که بر مشکل محو شدگی گرادیان در آموزش شبکههای عصبی پیشرو با الگوریتم پسانتشار، غلبه کنند. این شبکهها مدلهای بدون ناظر هستند که بازنمایی ویژگیهای نهفتهی نقاط دادهای را تولید میکنند. درواقع ماشین بولتزمن محدود شده با بررسی و تحلیل دادههای ورودی توزیع احتمالی ذاتی آنها را به دست میآورد و میتواند برای تولید دادههای مشابه مورد استفاده قرار گیرد. ماشین بولتزمن فقط دو لایه دارد. یک لایهی پنهان و یک لایهی آشکار که در آنها نورونهای یک لایه با هم ارتباط ندارند و فقط ارتباط بین نورونهای از دو لایهی متفاوت است. با هدف افزایش قدرت بازنمایی چندین ماشین بولتزمن با یکدیگر ترکیب شده و از ترکیب آنها شبکههای گوناگونی ساخته شده است. نمونههایی از آنها ماشین بولتزمن عمیق (Deep Boltzman Machine) و شبکهی باور عمیق (Deep Belief Network) هستند که در نمودار شکل ۱ دیده میشوند. نوع دیگری از همین شبکههای ترکیبی شبکهی بولتزمن محدود شدهی عمیق (Deep Restricted Boltzman Network) است که نسبت به بقیه قویتر بوده و ویژگیهای با کیفیت بالاتری را استخراج مینماید.
نوع بعدی از معماریهای یادگیری عمیق، شبکههای عصبی بازگشتی (RNN) هستند. این شبکهها برای دادههایی که بین آنها وابستگیهای زمانی و وابستگیهای ترتیبی وجود دارد، مثل متن و سری زمانی، مناسب هستند. سایر معماریهای معرفی شده در این نوشتار این قابلیت را ندارند و در آنها به وابستگیهای زمانی توجه نشده است. حتی شبکه عصبی کانولوشن نیز که به وابستگیهای بین دادهها اهمیت میدهد، به وابستگیهای مکانی توجه دارد و نه زمانی. از طرفی اگر دادهی ورودی طول متغیر داشته باشد استفاده از شبکههای عصبی بازگشتی میتواند بسیار مناسب باشد و سایر شبکههای مذکور در این یادداشت به دلیل اینکه ورودی با طول ثابت دریافت میکنند با چنین دادههایی با چالش مواجه میشوند و نمیتوانند آن را حل نمایند.
در شبکههای عصبی بازگشتی بجای اینکه ورودیها در یک لایهی ورودی دریافت شوند، هر ورودی در یک لایه دریافت میشود. ورودیها به ترتیبی که برای آنها مقرر شده در لایههای متوالی دریافت میشوند و در هر لایه فقط یک ورودی دریافت خواهد شد. به عبارت دیگر معماری شبکههای بازگشتی مبتنی بر ذات توالی دادههای ورودی، به صورت لایههای متوالی طراحی شده است. البته این لایهها کاملاً از یکدیگر مستقل نیستند و پارامترهای خود را با یکدیگر به اشتراک میگذارند. درواقع در شبکهی عصبی بازگشتی تنها یک لایه داریم که به تعداد دادههای ورودی به صورت تکراری مورد استفاده قرار میگیرد. این لایه خروجی خود را بر اساس دو ورودی محاسبه میکند. یک ورودی از دنبالهی دادههای ورودی شبکه و یکی دیگر از خروجی مرحلهی قبل.
از آنجایی که یک تناظر یک به یک بین لایهها و موقعیتهای خاص در دنبالهی ورودی وجود دارد، شبکه میتواند به راحتی دادههای با طول متغیر را دریافت کند. به صورت همزمان وابستگیهای زمانی بین دادههای ورودی نیز در نظر گرفته میشود. از آنجایی که شبکه عصبی بازگشتی فقط یک لایه دارد که در زمانمهرهای متوالی تکرار میشود، با افزایش اندازهی ورودی و در نتیجهی آن افزایش زمانمهرها و لایههای زمانی پارامترهای شبکه ثابت میمانند و تغییری در حجم آنها اتفاق نمیافتد.
محو شدگی گرادیان و انفجار گرادیان از مسائل و چالشهای معمول شبکههای بازگشتی (RNN) است. به همین دلیل برای غلبه بر این مشکلات شبکههای LSTM و GRU ارائه شدهاند. در این شبکهها سعی شده است که با استفاده از حافظهی بلند مدت مسائل و مشکلات RNN برطرف شود. در یادداشتهای بعدی در همین وبلاگ جزئیات بیشتری در خصوص این معماریها ارائه خواهد شد.
منابع:
Goodfellow, I., Bengio, Y., Courville, A., 2016. Deep learning, Adaptive computation and machine learning. The MIT Press, Cambridge, Massachusetts.
Pedrycz, W., Chen, S.-M. (Eds.), 2020. Deep Learning: Concepts and Architectures, Studies in Computational Intelligence. Springer International Publishing, Cham. https://doi.org/10.1007/978-3-030-31756-0


























