TDM: Trajectory Data Minning
دادهکاوی خط سیرTDM: Trajectory Data Minning
دادهکاوی خط سیر
پرسپترون چند لایه
شبکهی پرسپترون که در دههی ۱۹۶۰ توسط روزنبلات ارائه شد یک لایهی ورودی و یک لایهی خروجی داشت. در این شبکه فقط لایهی خروجی، لایهی محاسباتی بود و لایهی ورودی تنها به انتقال دادههای ورودی به لایهی خروجی میپرداخت. در لایهی خروجی نیز پس از انجام محاسبات، خروجیهای شبکه بدست میآمدند. گرچه این یک دستاورد چشمگیر بود که میتوانست یاد بگیرد اما مینسکی و پاپرت در کتاب خود (Minsky and Papert, 1969) در سال ۱۹۶۹ نشان دادند که شبکهی پرسپترون مسائل غیر خطی مانند XOR را نمیتواند حل کند. راه حل آن هم استفاده از لایههای بیشتر در این شبکه عصبی است که به آن پرسپترون چند لایه (Multilayer Perceptron یا به اختصار MLP) میگویند. با وجود اینکه راه حل مشخص بود اما سالها طول کشید تا بتواند عملیاتی شود و در شبکههای عصبی به صورت عملی مورد استفاده قرار گیرد. پس از آن نیز با وجود آنکه این شبکه در عمل تواناییهای خود را نشان داد، آنچه که به صورت ریاضی و نظری در مورد آن اثبات شده بود عملاً تحقق نیافت و در کاربردهای یادگیری عمیق با چالشهایی مواجه شد.
در مورد این روند تاریخی، قبل از این یادداشتی با نام «داستان فراز و فرودهای شبکههای عصبی» در همین وبلاگ منتشر شده است. در نوشتار حاضر به صورت خلاصه به معرفی شبکه عصبی پرسپترون چند لایه میپردازیم، معماری آن را مورد بررسی قرار داده و مسائل و مشکلاتی را که در حل مسائل یادگیری عمیق با آنها مواجه است معرفی میکنیم.
در شکل ۱ یک مثال از شبکه عصبی پرسپترون چند لایه نشان دهده شده است. همانگونه که در این شکل دیده میشود، پرسپترون چندلایه یک لایهی ورودی دارد و یک لایهی خروجی و یک یا چند لایه از نورونها نیز بین آنها وجود دارند. از آنجایی که لایههای میانی به صورت مستقیم به ورودی و خروجی متصل نیستند، به آنها لایهی پنهان گفته میشود. واحدهای لایهی ورودی هیچ عملیات محاسباتی روی ورودیها انجام نمیدهند بلکه وظیفهی آنها توزیع دادههای ورودی بین واحدهای لایهی بعدی است. بنابراین اغلب در شمارش، لایهها شمرده نمیشوند. بنابراین در شکل ۱ با اینکه دو لایهی پنهان، یک لایهی خروجی و یک لایهی ورودی دیده میشود، یک شبکهی پرسپترون سه لایه داریم.
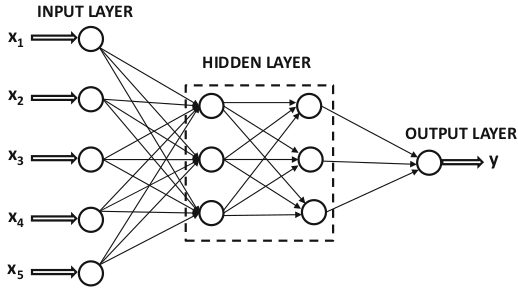
شکل
۱-
شبکهی
عصبی چندلایه بدون بایاس (Aggarwal,
2018)
نحوهی عمل پرسپترون چند لایه مشابه پرسپترون تک لایه است. با این تفاوت که در آن چندین لایهی محاسباتی داریم. عملکرد این شبکه به اینصورت است که در ابتدا الگویی به شبکه عرضه میگردد. سپس محاسبات روی الگوی ورودی در اولین لایهی محاسباتی انجام شده و نتیجهی آن به لایهی بعدی ارسال میشود. در هر لایه، محاسبات روی ورودیهای آن لایه انجام شده و خروجی بدست آمده از آن لایه به عنوان ورودی لایهی بعدی، به لایهی بعد انتقال مییابد. این کار تا جایی انجام میشود که در لایهی آخر، خروجی نهایی بدست آید که خروجی کل شبکه است.
همانگونه که از فرایند انجام محاسبات مشخص است، در شبکههای عصبی پرسپترون چندلایه دادهها در یک جهت حرکت میکنند. همیشه دادهها از لایهی ورودی وارد شده، لایه به لایه به سمت خروجی حرکت کرده و از لایهی خروجی خارج میشوند. این معماری را شبکه عصبی پیشرو (feedforward) مینامند زیرا لایهها به صورت متوالی از ورودی به خروجی به هم وصل میشوند (Aggarwal, 2018).
در شکهی پرسپترون چند لایه میتوان خروجی هر لایه را به صورت یک بردار نوشت. از اینرو معمولاً محاسبات در این شبکهها به صورتبرداری انجام میشود. برای این منظور لازم است که وزن روی یالها به صورت ماتریسهای وزن نوشته شوند. توابع فعال سازی در نورونهای هر لایه نیز یکسان هستند. به همین دلیل میتوانیم با عملیات برداری و محاسبات ماتریسی از بردار ورودی هر لایه بردار خروجی آن را بدست آوریم. به همین دلیل است که بسیاری از نمودارهای معماری بجای استفاده از تعدادی دایره، هر لایه را به صورت یک مستطیل نمایش میدهند. در شکل ۲ نمایش اسکالر یک شبکهی پرسپترون چندلایه و در شکل ۳ نمایش برداری همان شبکه نشان داده شده است.
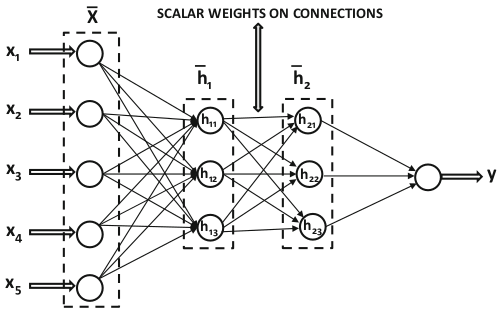
شکل
۲-
نمایش
اسکالر شبکه عصبی پرسپترون چندلایه
(Aggarwal,
2018)
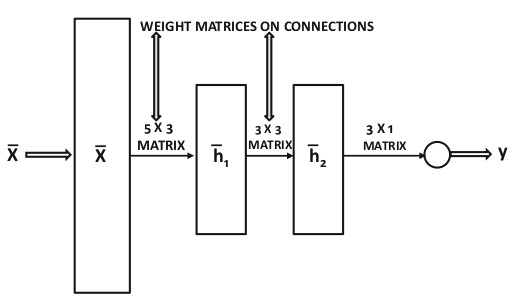
شکل
۳-
نمایش
برداری
شبکه عصبی پرسپترون چندلایه که
در شکل ۵ نشان داده شده
(Aggarwal,
2018)
در سال ۱۹۸۹ ثابت شد (Hornik et al., 1989) که شبکههای عصبی پرسپترون چندلایه قادر هستند هر مسئلهی خطی و غیر خطی را حل کنند. البته این اثبات با این فرض انجام شد که قدرت محاسباتی کامپیوترها نامحدود است. این در حالی است که سختافزارهای آن زمان نمیتوانستند قدرت محاسباتی لازم برای حل همهی مسائل را فراهم کنند. سالها بعد هیتنون و همکارانش در دههی اول قرن ۲۱ از پردازندههای گرافیکی برای افزایش قدرت محاسباتی استفاده کردند.
عامل اصلی در افزایش حجم محاسبات در این شبکهها افزایش تعداد لایههای شبکه است. درواقع به شبکههای عصبی که شامل کمتر از ۳ لایه هستند شبکههای عصبی کمعمق (shallow neural networks) گفته میشود و آنهایی که تعداد لایههای بیشتر دارند با عنوان شبکه عصبی عمیق شناخته میشوند. بسیاری از مدلهای یادگیری ماشین را میتوان با شبکههای عصبی کمعمق پیادهسازی کرد. این امر نشان دهندهی قدرت شبکههای عصبی است. معماریهای عمیقتر اغلب با ترکیب و پشتهسازی از مدلهای سادهتر ساخته میشوند (Aggarwal, 2018). تعداد لایههای بیشتر این امکان را فراهم میکنند که شبکه بتواند ویژگیهای بیشتری از الگوها را یاد بگیرد و الگوهای پیچیدهتری را تشخیص دهد.
البته غیر از قدرت محاسباتی سختافزارها مسئلهی مهم دیگری نیز برای عملی شدن شبکههای عصبی عمیق مطرح بود. آن هم الگوریتم آموزش شبکههای پرسپترون چندلایه بود. در پرسپترون چندلایه نیز مانند پرسپترون یک لایه مقایسهی خروجی با خروجی مطلوب ملاک تغییر وزنها و آموزش شبکه است. اما این کار فقط در لایهی آخر امکانپذیر است. چون خروجی مطلوب فقط برای آخرین لایه در دسترس است و برای لایههای قبل از آن خروجی مطلوب مشخص نیست. از سال ۱۹۶۹ تا سال ۱۹۸۶ طول کشید تا راه حلی برای این مسأله پیدا شود. دورهای که با نام زمستان شبکههای عصبی از آن یاد میشود. در این سال David Rumelhart،و Geoffery Hinton و Ronald Williams پیشنهاد Werbos برای استفاده از پسانتشار (backpropagation) در آموزش شبکههای عصبی چندلایه (Werbos, 1974) را در یک مسألهی یادگیری بازنمایی به کار بستند (Rumelhart et al., 1986) و نشان دادند که این الگوریتم به درستی کار میکند. این کار نقطهی تحولی در شبکههای عصبی بود و پس از آن شبکههای عصبی چندلایه با استفاده از الگوریتم پس انتشار برای طیف وسیعی از مسائل در عرصههای مختلف کاربردی به کار گرفته شد. البته این پایان کار نبود. با افزایش تعداد لایهها، شبکههای عصبی پرسپترون چند لایه با مسائل و مشکلات متعددی مواجه میشوند.
الگوریتم پسانتشار برای استفاده در شبکههای با تعداد لایههای زیاد با چالشهایی مواجه است که مهمترین آنها بیشبرازش (Overfitting) است (Aggarwal, 2018). مسألهی بیشبرازش به شرایطی اشاره دارد که در آن، شبکه با مجموعهی آموزشی کاملاً منطبق میشود و نقاط آن را کاملاً دقیق پیشبینی میکند. اما در مواجهه با دادههای جدید که در مجموعهی آموزشی نیستند به خوبی عمل نمیکند و ممکن است که خطای زیادی در پیشبینی داشته باشد. این شرایط زمانی اتفاق میافتد که در زمان آموزش، خطای خروجی را به صفر برسانیم. بنابراین انطباق یک مدل بر یک مجموعه آموزشی خاص، ضمانت نمیکند که دادههای آزمایشی دیده نشده را به درستی پیشبینی نماید؛ حتی اگر دادههای آموزشی را با دقت بالا پیشبینی کرده باشد. البته همیشه شکافی بین کارایی شبکه در کار با دادههای آموزشی و کارایی آن در کار با دادههای آزمایشی وجود دارد. این شکاف به ویژه وقتی با مدلهای پیچیده و مجموعه دادههای آموزشی کوچک کار میکنیم بزرگتر میشود (Aggarwal, 2018).
وقتی تعداد لایهها در شبکهی عصبی زیاد شود الگوریتم پسانتشار با مشکلاتی مواجه میشود. الگوریتم برای انتشار رو به عقب خطا از قاعدهی زنجیرهای مشتق استفاده میکند. و دقیقاً همین قاعده نقطهی ضعف الگوریتم در شبکههای با تعداد لایههای زیاد است. به دلیل مشتقهای متوالی خطایی که به لایههای ابتدایی میرسد بسیار کوچک و در حد صفر است. این امر باعث میشود که به روز رسانی وزنها در لایههای اولیه بسیار کوچک بوده و یا انجام نشود. این مشکل به نام محو شدگی گرادیان (vanishing gradient) شناخته میشود. در انواع خاصی از معماریهای شبکه، زنجیرهی مشتق باعث بزرگ شدن بیش از حد یکی از مقادیر نسبت به سایر مقادیر میشود که به آن انفجار گرادیان (exploding gradient) گفته میشود (Aggarwal, 2018).
وقتی عمق شبکه خیلی زیاد باشد حفظ سرعت مناسب همگرایی برای فرایند بهینهسازی بسیار سخت میشود. زیرا با افزایش عمق، مقاومت در برابر یادگیری نیز بیشتر میشود. این مسئله به محو شدگی گرادیان مربوط میشود، اما ویژگیهای خاص خود را دارد. بنابراین روشهایی در مقالات مختلف برای این مورد ارائه شده است (He et al., 2016).
تابع بهینهسازی شبکهی عصبی بسیار غیرخطی است که باعث میشود تعداد زیادی نقطهی کمینه یا بهینهی محلی داشته باشد. یکی از مشکلات شبکههای عصبی این است که شبکه ممکن است در این کمینههای محلی گرفتار شود و از رسیدن به نقطهی بهینهی کلی باز ماند. برای این مشکل راه حلهای مختلفی ارائه شده که پرداختن به آنها از موضوع اصلی این گزارش فاصله دارد. از بین آنها تنها به پیش آموزش شبکه اشاره میکنیم که یکی از متدهایی بود که در راه بهبود شبکههای عصبی منجر به پیدایش یادگیری عمیق شد.
یکی از واضحترین چالشهایی که شبکههای عصبی مصنوعی همیشه با آن رو به رو بوده و هستند، مسئلهی نیاز به قدرت محاسباتی است که قبل از این نیز به آن اشاره کردیم. در سالهای گذشته، مخصوصاً در دههی ۱۹۹۰ و ۲۰۰۰ میلادی، تلاشهای زیادی برای رفع همهی این موانع انجام شد. نتیجهی این تلاشها مجوعهای از روشها و معماریها است که امروزه آنها را با نام یادگیری عمیق میشناسیم.
منابع:
Aggarwal, C.C., 2018. Neural Networks and Deep Learning: A Textbook. Springer International Publishing, Cham. https://doi.org/10.1007/978-3-319-94463-0
He, K., Zhang, X., Ren, S., Sun, J., 2016. Deep Residual Learning for Image Recognition, in: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Presented at the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Las Vegas, NV, USA, pp. 770–778. https://doi.org/10.1109/CVPR.2016.90
Hornik, K., Stinchcombe, M., White, H., 1989. Multilayer feedforward networks are universal approximators. Neural Netw. 2, 359–366. https://doi.org/10.1016/0893-6080(89)90020-8
Minsky, M., Papert, S., 1969. An introduction to computational geometry. Camb. Tiass HIT 479, 480.
Rumelhart, D.E., McClelland, J.L., Group, P.R., 1986. Parallel distributing Processing: Explorations in the Microstructures of Cognition. Cambridge, Mass: MIT Press.
Werbos, P.J., 1974. Beyond Regression: New Tools for Prediction and Analysis in the Behavioral Sciences. Cambridge, MA: Harvard University. Ph. D. thesis, 906p.


























