TDM: Trajectory Data Minning
دادهکاوی خط سیرTDM: Trajectory Data Minning
دادهکاوی خط سیر
شبکه عصبی هاپفیلد
شبکههای هاپفیلد در سال ۱۹۸۰ میلادی توسط John Hopfield معرفی شدند. وی تحقیقاتی در زمینهی مسألهی خود انجمنی داشته و تجزیه و تحلیلهای عمیقی روی شبکههای عصبی انجام داده است. همین پژوهشها او را در عرصهی هوش مصنوعی و یادگیری ماشین به چهرهای شناخته شده بدل کرده. در شکل ۱ و شکل ۲ دو نمایش از معماری شبکهی هاپفیلد نشان داده شده است. همانگونه که در این شکلها دیده میشود هر شبکهی هاپفیلد از تعدادی گره تشکیل شده و در آن هر گره به تمام گرههای دیگر متصل است. به عبارت دیگر هر گره ورودی خود را از همهی گرههای دیگر دریافت کرده و خروجی هر گره به عنوان ورودی به همهی گرههای دیگر ارسال میشود.
شبکهی هاپفیلد از نظر ضرایب وزنی متقارن است و مقدار وزن یالهای بین دو گره در هر دو جهت بایکدیگر برابرند. گرهها مانند شبکهی پرسپترون دارای یک سطح آستانه و یک تابع پلکانی هستند و مثل پرسپترون عمل میکنند. ورودیها و خروجیهای هر گره به صورت دودویی یعنی صفر و یک (۱ ،۰) و یا به صورت دو قطبی یعنی (۱+ ،۱-) هستند. مقادیر خروجیهای گرههای شبکه در کنار یکدیگر برداری را تشکیل میدهند که به آن بردار حالت شبکه میگوییم.
در شبکهی هاپفیلد ورودی و خروجی مشخصی وجود ندارد. در انواع دیگر شبکههای عصبی گرههایی که ورودیهای خود را از دیگر گرهها دریافت نمیکنند به عنوان گرههای لایهی ورودی محسوب میشوند و لایهی خروجی نیز شامل گرههایی است که خروجی آنها به هیچ گره دیگری داده نمیشود. اما در شبکهی هاپفیلد هر گره ورودیهای خود را از سایر گرهها دریافت میکند و خروجی خود را به سایر گرهها میفرستد. بنابراین ساختار لایهای که در شبکههای عصبی پیشرو دیده میشود در شبکهی هاپفیلد وجود ندارد. به همین علت عملکرد این شبکه با سایر شبکهها متفاوت است (Beale and Jackson, 1994).

شکل
۱-
معماری
شبکهی هاپفیلد (Beale
and Jackson, 1994)

شکل
۲-
نمایشی
دیگر از معماری شبکهی هاپفیلد (Beale
and Jackson, 1994)
در شروع کار به صورت همزمان ورودی شبکه (حالت اولیه) به شکل یک بردار دودویی یا دو قطبی، به صورت تحمیلی به خروجیهای گرههای شبکه اعمال میشود. از آنجایی که خروجی هر گره به ورودی همهی گرههای دیگر متصل است، بنابراین هر گره ورودی لازم برای محاسبهی خروجی را خواهد داشت. با محاسبهی خروجی گرهها حالت شبکه عوض میشود. همین بردار حالت، ورودی مرحلهی بعدی است. در شبکههای عصبی پیشرو در هر مرحله، بردار ورودی از مجموعه دادههای ورودی به شبکه اعمال میشود. اما در شبکهی هاپفیلد فقط در شروع کار بردار ورودی از خارج از شبکه اعمال میشود و برای مراحل بعدی خروجی هر مرحله (بردار حالت) ورودی مرحلهی بعدی است. بنابراین در خلال تغییر حالتهای مراحل مختلف چرخهی شبکه، ورودی جدیدی از خارج از شبکه اعمال نمیشود. این چرخه ادامه مییابد تا زمانی که شبکه به حالتی ثابت و پایدار همگرا شود. حالت ثابت و پایدار به عنوان خروجی شبکه تلقی میشود.
بر اساس آنچه که گفته شد یادگیری در شبکهی هاپفیلد با شبکههای دیگر متفاوت است. در ادامهی مطالب، مراحل الگوریتم شبکهی هاپفیلد بیان میشود:
مرحلهی اول: ضرایب وزنی با استفاده از فرمول زیر تعیین میشوند.

که در آن Wij ضریب وزنی از گره i به گره j بوده و xis عضو iام الگوی نمونهی s است. مقدار Wij یا ۱+ است یا ۱-. M نیز تعداد الگوها را مشخص میکند.
در این مرحله ضرایب وزنی بین نورونها با استفاده از الگوهای نمونهی انتخابی از تمام طبقهها تعیین میگردد. این مرحله، مرحلهی آموزش شبکه است که هر الگو را به خودش نظیر میکند.
مرحلهی دوم: الگوی ناشناخته به شبکه عرضه میشود.
![]()
در اینجا μi(t) خروجی گرهی iام در زمان t است.
مرحلهی سوم: تا همگرایی کامل، محاسبات زیر تکرار میشود.
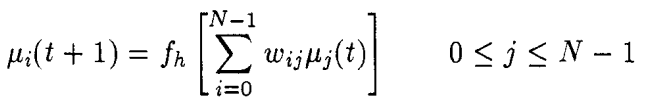
در اینجا تابع fh یک تابع غیر خطی پلکانی است.
بعد از تنظیم وزنها و آموزش شبکه، خروجی به صورت تحمیلی برابر با الگوی ناشناخته قرار میگیرد. آنگاه شبکه رها میشود تا آزادانه در فواصل زمانی گسسته مکرراً تغییر حالت دهد تا جایی که به حالت پایداری رسیده و خروجی آن وضع ثابتی پیدا کند. به این طریق شبکه به جواب نهایی خود همگرا میشود. این ویژگی باعث میشود که اگر الگوی درهمی به شبکه داده شود شبکه الگوی سالم آن را تولید کند. بنابراین شبکه به صورت یک حافظهی قابل آدرس دهی محتوایی عمل میکند (Beale and Jackson, 1994).
شبکهی هاپفیلد از یک مدل بهینهسازی برای یادگیری پارامترهای وزن استفاده میکند تا وزنها بتوانند روابط مثبت و منفی بین ویژگیهای مجموعههای آموزشی را ثبت کنند. تابع هدف (objective function) در یک شبکهی هاپفیلد با نام تابع انرژی (energy function) نیز شناخته میشود که همانند تابع ضرر (loss function) در شبکههای عصبی پیشرو (feedforward neural networks) سنتی است. تابع انرژی یک شبکهی هاپفیلد به گونهای تنظیم شده است که زوج ندهای متصل با وزنهای مثبت بزرگ را به داشتن حالتهای مشابه، و زوج ندهای متصل با وزنهای منفی بزرگ را به داشتن حالتهای متفاوت ترغیب میکند. بنابراین مرحلهی آموزش شبکهی هاپفیلد وزنهای یالها را به منظور کمینه کردن انرژی، زمانی که حالتهای شبکه به مقادیر ویژگیهای باینری در نقاط آموزشی منحصر به فرد ثابت میشوند، یاد میگیرد. بنابراین یادگیری وزنهای شبکهی هاپفیلد تلویحا یک مدل بدون ناظر میسازد (Aggarwal, 2018).
تابع انرژی نمایانگر انحراف خروجی واقعی شبکه از خروجی مطلوب است. اختلافهای زیاد ناشی از انرژی زیاد واختلافهای کم ناشی از انرژی کم است. از آنجایی که خروجی شبکه به پارمترهای ضرایب وزنی شبکه مربوط است، انرژی نیز تابعی از ضرایب وزنی و ورودی خواهد بود. بنابراین میتوانیم نمودار تابع انرژی را به شکلی رسم کنیم که نحوهی تأثیر تغییرات پارامترهای شبکه بر تغییرات انرژی را نشان دهد. به عنوان مثال اگر یک شبکهی پیچیده را در نظر بگیریم و تغییرات تابع انرژی را بر حسب تغییرات یکی از ضرایب وزنی آن رسم کنیم ممکن است شکلی مانند شکل ۳ داشته باشیم.
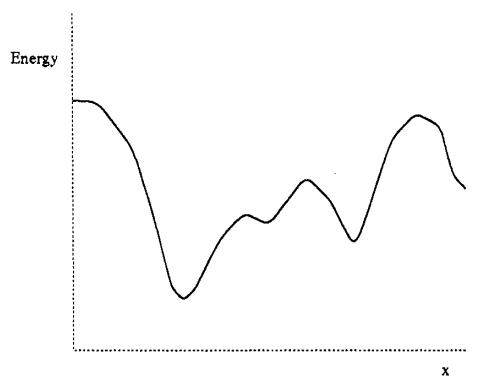
شکل
۳-
تابع
انرژی بر حسب تغییرات یکی از ضرایب وزنی
(Beale
and Jackson, 1994)
اگر تغییرات دو ضریب وزنی را در نظر بگیریم آنگاه نمودار سه بعدی شکل ۴ را خواهیم داشت. درواقع معمولاً در شبکههای عصبی تعداد پارامترها بیش از این است. بنابراین تابع انرژی اغلب ابعاد بالایی خواهد داشت البته رسم نمودارهای با ابعاد بالاتر امکانپذیر نیست و شکل تابع انرژی قابل تصور نخواهد بود. از اینرو تا حد امکان آن را به صورت صفحهای سه بعدی تصور میکنیم.
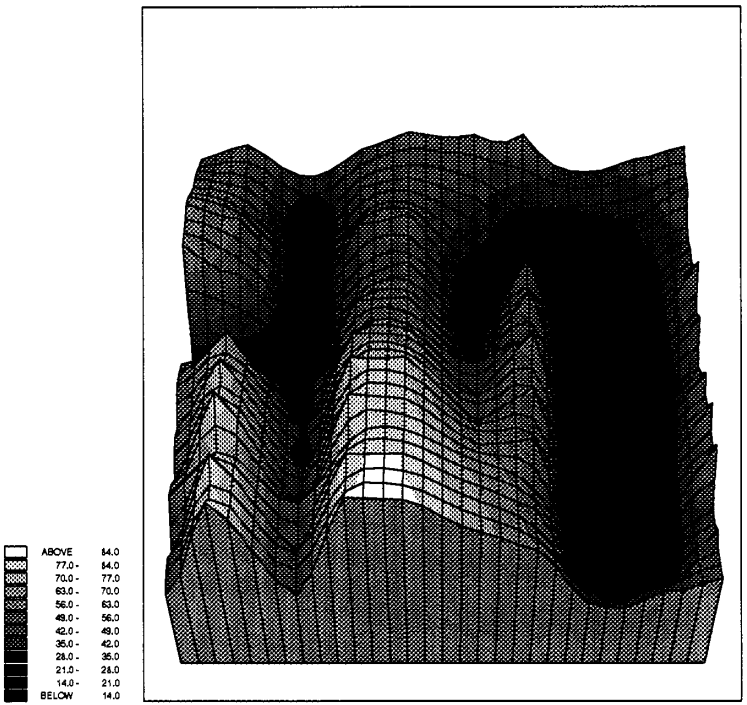
شکل
۴-
تابع
انرژی بر حسب تغییرات دو ضریب وزنی (Beale
and Jackson, 1994)
همانگونه که در شکل ۴ دیده میشود، صفحهی انرژی همچون چشماندازی مواج، پوشیده از تپهها و درهها، چالهها و کوهها است. یک الگوی ناشناخته حکم نقطهای را روی صفحهی انرژی دارد. به تدریج که شبکه در چرخهی فرایند تکراری به سمت جواب همگرا میشود، این نقطه روی صفحهی انرژی به سوی یکی از چالهها حرکت میکند. جواب وقتی حاصل میشود که این نقطه به عمیقترین موضع در صفحه میرسد و از آنجا که همهی نقاط اطراف آن در موقعیت با انرژی بالاتری قرار دارند در همان موضع پایدار میماند. هر یک از چالههای صفحهی انرژی نشان دهندهی حالات پایدار شبکه بوده و نمایندهی یکی از الگوهای ذخیره شده در شبکهاند. چالهها نقاطی با کمترین انرژی هستند که در شکل تیرهتر نشان داده شده و قلهها نقاط با بیشترین انرژی هستند که با رنگ روشن نشان داده شدهاند.
برای محاسبهی تابع انرژی در پرسپترون علاوه بر خروجی واقعی شبکه، به خروجی مطلوب شبکه نیز نیاز است. لیکن در شبکهی هاپفیلد که به تدریج به جواب نزدیک میشود، اطلاعی از خروجی حالات میانی در دست نیست. بنابراین به روش دیگری برای محاسبهی تابع انرژی نیاز داریم که با ساختار این شبکه سازگار باشد. مقدار این تابع باید با خطا نسبت مستقیم داشته باشد و اندازهی ضرایب وزنی و الگوهای عرضه شده به شبکه نیز باید بر مقدار آن تأثیر گذار باشند. تابع زیر این ویژگیها را دارد.
![]()
در اینجا wij نمایانگر ضرایب وزنی بین گرهی i و گرهی j بوده، si حالت یا خروجی گرهی i است که در رابطههای قبلی با xi نیز نشان داده شده، و bi مقدار بایاس یا آستانهی گرهی i است (Aggarwal, 2018). ضرایب وزنی شبکه حاوی اطلاعات الگوها میباشد و بدین صورت کلیهی الگوها به نحوی در تابع انرژی گنجانده شدهاند.
بررسی جزئیات آموزش این شبکه از حوصلهی این نوشتار خارج است. ولی نگاه کوتاهی به آن خواهیم داشت. برای رسیدن به انرژی کمینه میتوان سهم هر گره از تابع انرژی را محاسبه کرده و در حرکت از یک حالت به حالت بعدی شبکه، مقدار آن را کاهش داد. اختلاف انرژی شبکه برای موردی که حالت si برابر یک و در موردی که si برابر صفر است به صورت زیر محاسبه میشود که به آن شکاف انرژی یا energy gap گفته میشود (Aggarwal, 2018):
![]()
برای بررسی جزئیات بیشتر در زمینهی آموزش شبکهی هاپفیلد و تحلیل انرژی به منابع مربوطه که در انتهای یادداشت معرفی شدهاند مراجعه نمایید.
منابع:
Aggarwal, C.C., 2018. Neural Networks and Deep Learning: A Textbook. Springer International Publishing, Cham. https://doi.org/10.1007/978-3-319-94463-0
Beale, R., Jackson, T., 1994. Neural computing: an introduction. Institute of physics publ, Bristol Philadelphia.


























